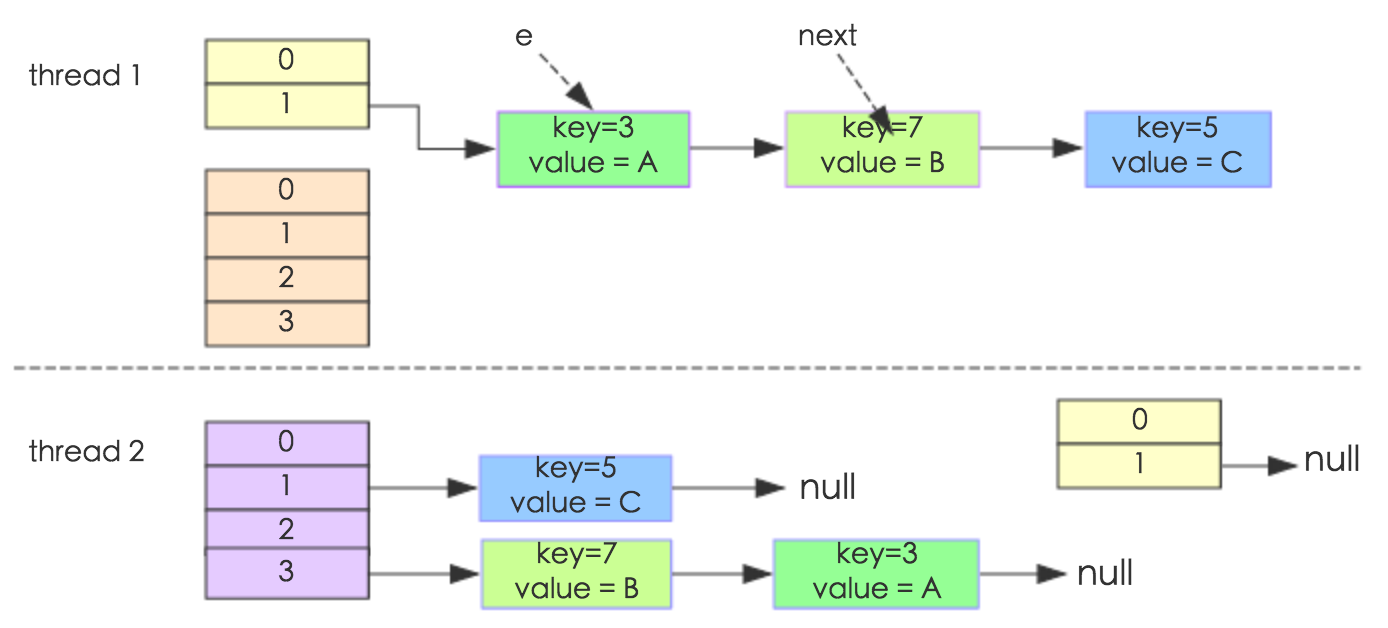
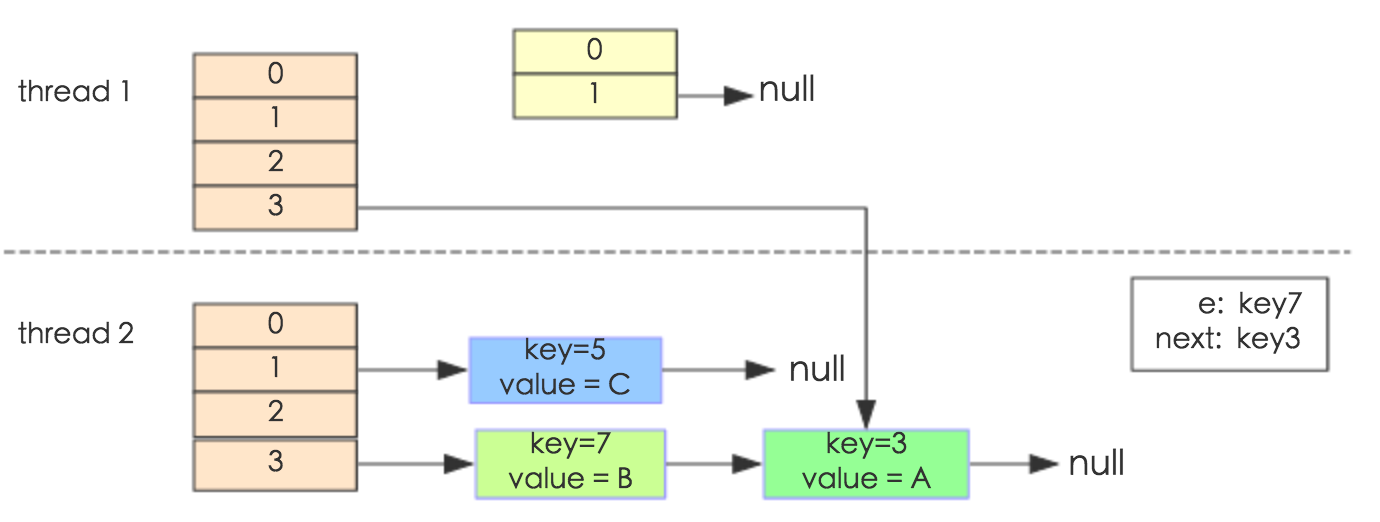
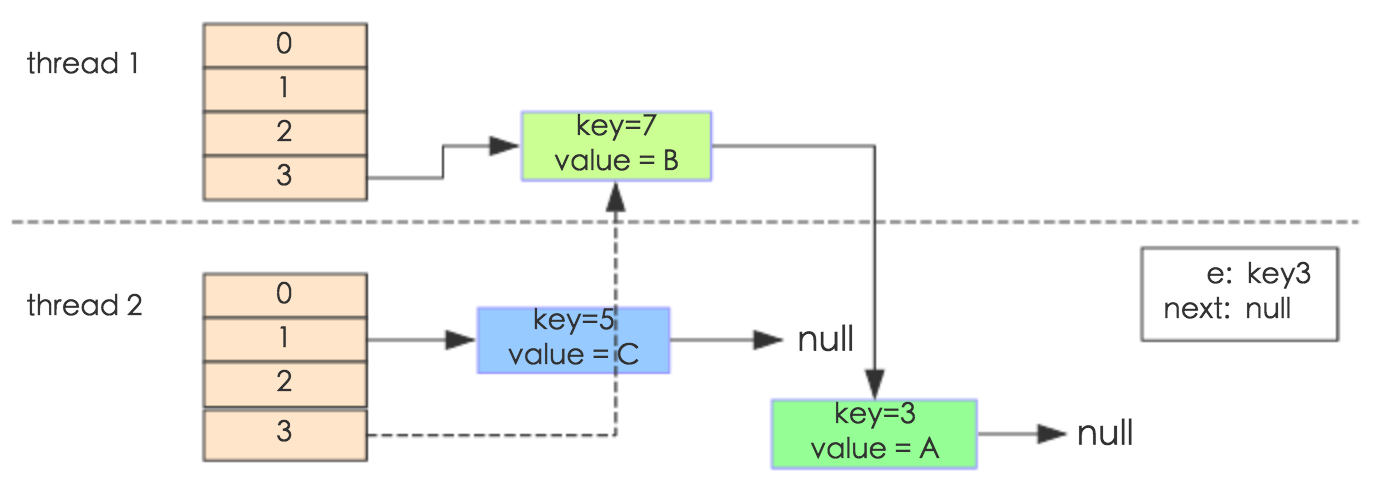
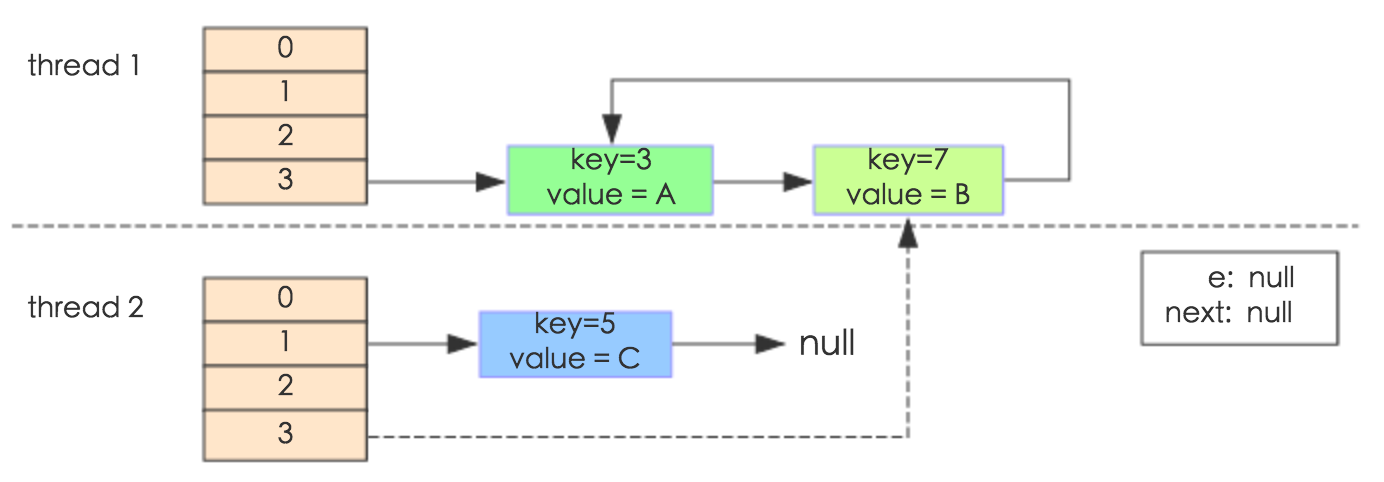
package java.util;
import java.io.IOException;
import java.io.InvalidObjectException;
import java.io.ObjectInputStream;
import java.io.Serializable;
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.util.function.BiConsumer;
import java.util.function.BiFunction;
import java.util.function.Consumer;
import java.util.function.Function;
import sun.misc.SharedSecrets;
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
static Class<?> comparableClassFor(Object x) {
if (x instanceof Comparable) {
Class<?> c; Type[] ts, as; Type t; ParameterizedType p;
if ((c = x.getClass()) == String.class)
return c;
if ((ts = c.getGenericInterfaces()) != null) {
for (int i = 0; i < ts.length; ++i) {
if (((t = ts[i]) instanceof ParameterizedType) &&
((p = (ParameterizedType)t).getRawType() ==
Comparable.class) &&
(as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c)
return c;
}
}
}
return null;
}
@SuppressWarnings({"rawtypes","unchecked"})
static int compareComparables(Class<?> kc, Object k, Object x) {
return (x == null || x.getClass() != kc ? 0 :
((Comparable)k).compareTo(x));
}
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int size;
transient int modCount;
int threshold;
final float loadFactor;
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) {
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1;
}
else if (oldThr > 0)
newCap = oldThr;
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<K> iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
public Collection<V> values() {
Collection<V> vs = values;
if (vs == null) {
vs = new Values();
values = vs;
}
return vs;
}
final class Values extends AbstractCollection<V> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<V> iterator() { return new ValueIterator(); }
public final boolean contains(Object o) { return containsValue(o); }
public final Spliterator<V> spliterator() {
return new ValueSpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super V> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.value);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new EntrySet()) : es;
}
final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator();
}
public final boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Node<K,V> candidate = getNode(hash(key), key);
return candidate != null && candidate.equals(e);
}
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
public final Spliterator<Map.Entry<K,V>> spliterator() {
return new EntrySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super Map.Entry<K,V>> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
@Override
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? defaultValue : e.value;
}
@Override
public V putIfAbsent(K key, V value) {
return putVal(hash(key), key, value, true, true);
}
@Override
public boolean remove(Object key, Object value) {
return removeNode(hash(key), key, value, true, true) != null;
}
@Override
public boolean replace(K key, V oldValue, V newValue) {
Node<K,V> e; V v;
if ((e = getNode(hash(key), key)) != null &&
((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) {
e.value = newValue;
afterNodeAccess(e);
return true;
}
return false;
}
@Override
public V replace(K key, V value) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) != null) {
V oldValue = e.value;
e.value = value;
afterNodeAccess(e);
return oldValue;
}
return null;
}
@Override
public V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
if (mappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
V oldValue;
if (old != null && (oldValue = old.value) != null) {
afterNodeAccess(old);
return oldValue;
}
}
V v = mappingFunction.apply(key);
if (v == null) {
return null;
} else if (old != null) {
old.value = v;
afterNodeAccess(old);
return v;
}
else if (t != null)
t.putTreeVal(this, tab, hash, key, v);
else {
tab[i] = newNode(hash, key, v, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
return v;
}
public V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (remappingFunction == null)
throw new NullPointerException();
Node<K,V> e; V oldValue;
int hash = hash(key);
if ((e = getNode(hash, key)) != null &&
(oldValue = e.value) != null) {
V v = remappingFunction.apply(key, oldValue);
if (v != null) {
e.value = v;
afterNodeAccess(e);
return v;
}
else
removeNode(hash, key, null, false, true);
}
return null;
}
@Override
public V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (remappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
}
V oldValue = (old == null) ? null : old.value;
V v = remappingFunction.apply(key, oldValue);
if (old != null) {
if (v != null) {
old.value = v;
afterNodeAccess(old);
}
else
removeNode(hash, key, null, false, true);
}
else if (v != null) {
if (t != null)
t.putTreeVal(this, tab, hash, key, v);
else {
tab[i] = newNode(hash, key, v, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
}
return v;
}
@Override
public V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
if (value == null)
throw new NullPointerException();
if (remappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
}
if (old != null) {
V v;
if (old.value != null)
v = remappingFunction.apply(old.value, value);
else
v = value;
if (v != null) {
old.value = v;
afterNodeAccess(old);
}
else
removeNode(hash, key, null, false, true);
return v;
}
if (value != null) {
if (t != null)
t.putTreeVal(this, tab, hash, key, value);
else {
tab[i] = newNode(hash, key, value, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
}
return value;
}
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key, e.value);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
@Override
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Node<K,V>[] tab;
if (function == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
e.value = function.apply(e.key, e.value);
}
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
@SuppressWarnings("unchecked")
@Override
public Object clone() {
HashMap<K,V> result;
try {
result = (HashMap<K,V>)super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
result.reinitialize();
result.putMapEntries(this, false);
return result;
}
final float loadFactor() { return loadFactor; }
final int capacity() {
return (table != null) ? table.length :
(threshold > 0) ? threshold :
DEFAULT_INITIAL_CAPACITY;
}
private void writeObject(java.io.ObjectOutputStream s)
throws IOException {
int buckets = capacity();
s.defaultWriteObject();
s.writeInt(buckets);
s.writeInt(size);
internalWriteEntries(s);
}
private void readObject(ObjectInputStream s)
throws IOException, ClassNotFoundException {
ObjectInputStream.GetField fields = s.readFields();
float lf = fields.get("loadFactor", 0.75f);
if (lf <= 0 || Float.isNaN(lf))
throw new InvalidObjectException("Illegal load factor: " + lf);
lf = Math.min(Math.max(0.25f, lf), 4.0f);
HashMap.UnsafeHolder.putLoadFactor(this, lf);
reinitialize();
s.readInt();
int mappings = s.readInt();
if (mappings < 0) {
throw new InvalidObjectException("Illegal mappings count: " + mappings);
} else if (mappings == 0) {
} else if (mappings > 0) {
float fc = (float)mappings / lf + 1.0f;
int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ?
DEFAULT_INITIAL_CAPACITY :
(fc >= MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY :
tableSizeFor((int)fc));
float ft = (float)cap * lf;
threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ?
(int)ft : Integer.MAX_VALUE);
SharedSecrets.getJavaOISAccess().checkArray(s, Map.Entry[].class, cap);
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] tab = (Node<K,V>[])new Node[cap];
table = tab;
for (int i = 0; i < mappings; i++) {
@SuppressWarnings("unchecked")
K key = (K) s.readObject();
@SuppressWarnings("unchecked")
V value = (V) s.readObject();
putVal(hash(key), key, value, false, false);
}
}
}
private static final class UnsafeHolder {
private UnsafeHolder() { throw new InternalError(); }
private static final sun.misc.Unsafe unsafe
= sun.misc.Unsafe.getUnsafe();
private static final long LF_OFFSET;
static {
try {
LF_OFFSET = unsafe.objectFieldOffset(HashMap.class.getDeclaredField("loadFactor"));
} catch (NoSuchFieldException e) {
throw new InternalError();
}
}
static void putLoadFactor(HashMap<?, ?> map, float lf) {
unsafe.putFloat(map, LF_OFFSET, lf);
}
}
abstract class HashIterator {
Node<K,V> next;
Node<K,V> current;
int expectedModCount;
int index;
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) {
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
final class ValueIterator extends HashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
final class EntryIterator extends HashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
static class HashMapSpliterator<K,V> {
final HashMap<K,V> map;
Node<K,V> current;
int index;
int fence;
int est;
int expectedModCount;
HashMapSpliterator(HashMap<K,V> m, int origin,
int fence, int est,
int expectedModCount) {
this.map = m;
this.index = origin;
this.fence = fence;
this.est = est;
this.expectedModCount = expectedModCount;
}
final int getFence() {
int hi;
if ((hi = fence) < 0) {
HashMap<K,V> m = map;
est = m.size;
expectedModCount = m.modCount;
Node<K,V>[] tab = m.table;
hi = fence = (tab == null) ? 0 : tab.length;
}
return hi;
}
public final long estimateSize() {
getFence();
return (long) est;
}
}
static final class KeySpliterator<K,V>
extends HashMapSpliterator<K,V>
implements Spliterator<K> {
KeySpliterator(HashMap<K,V> m, int origin, int fence, int est,
int expectedModCount) {
super(m, origin, fence, est, expectedModCount);
}
public KeySpliterator<K,V> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid || current != null) ? null :
new KeySpliterator<>(map, lo, index = mid, est >>>= 1,
expectedModCount);
}
public void forEachRemaining(Consumer<? super K> action) {
int i, hi, mc;
if (action == null)
throw new NullPointerException();
HashMap<K,V> m = map;
Node<K,V>[] tab = m.table;
if ((hi = fence) < 0) {
mc = expectedModCount = m.modCount;
hi = fence = (tab == null) ? 0 : tab.length;
}
else
mc = expectedModCount;
if (tab != null && tab.length >= hi &&
(i = index) >= 0 && (i < (index = hi) || current != null)) {
Node<K,V> p = current;
current = null;
do {
if (p == null)
p = tab[i++];
else {
action.accept(p.key);
p = p.next;
}
} while (p != null || i < hi);
if (m.modCount != mc)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super K> action) {
int hi;
if (action == null)
throw new NullPointerException();
Node<K,V>[] tab = map.table;
if (tab != null && tab.length >= (hi = getFence()) && index >= 0) {
while (current != null || index < hi) {
if (current == null)
current = tab[index++];
else {
K k = current.key;
current = current.next;
action.accept(k);
if (map.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
}
}
return false;
}
public int characteristics() {
return (fence < 0 || est == map.size ? Spliterator.SIZED : 0) |
Spliterator.DISTINCT;
}
}
static final class ValueSpliterator<K,V>
extends HashMapSpliterator<K,V>
implements Spliterator<V> {
ValueSpliterator(HashMap<K,V> m, int origin, int fence, int est,
int expectedModCount) {
super(m, origin, fence, est, expectedModCount);
}
public ValueSpliterator<K,V> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid || current != null) ? null :
new ValueSpliterator<>(map, lo, index = mid, est >>>= 1,
expectedModCount);
}
public void forEachRemaining(Consumer<? super V> action) {
int i, hi, mc;
if (action == null)
throw new NullPointerException();
HashMap<K,V> m = map;
Node<K,V>[] tab = m.table;
if ((hi = fence) < 0) {
mc = expectedModCount = m.modCount;
hi = fence = (tab == null) ? 0 : tab.length;
}
else
mc = expectedModCount;
if (tab != null && tab.length >= hi &&
(i = index) >= 0 && (i < (index = hi) || current != null)) {
Node<K,V> p = current;
current = null;
do {
if (p == null)
p = tab[i++];
else {
action.accept(p.value);
p = p.next;
}
} while (p != null || i < hi);
if (m.modCount != mc)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super V> action) {
int hi;
if (action == null)
throw new NullPointerException();
Node<K,V>[] tab = map.table;
if (tab != null && tab.length >= (hi = getFence()) && index >= 0) {
while (current != null || index < hi) {
if (current == null)
current = tab[index++];
else {
V v = current.value;
current = current.next;
action.accept(v);
if (map.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
}
}
return false;
}
public int characteristics() {
return (fence < 0 || est == map.size ? Spliterator.SIZED : 0);
}
}
static final class EntrySpliterator<K,V>
extends HashMapSpliterator<K,V>
implements Spliterator<Map.Entry<K,V>> {
EntrySpliterator(HashMap<K,V> m, int origin, int fence, int est,
int expectedModCount) {
super(m, origin, fence, est, expectedModCount);
}
public EntrySpliterator<K,V> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid || current != null) ? null :
new EntrySpliterator<>(map, lo, index = mid, est >>>= 1,
expectedModCount);
}
public void forEachRemaining(Consumer<? super Map.Entry<K,V>> action) {
int i, hi, mc;
if (action == null)
throw new NullPointerException();
HashMap<K,V> m = map;
Node<K,V>[] tab = m.table;
if ((hi = fence) < 0) {
mc = expectedModCount = m.modCount;
hi = fence = (tab == null) ? 0 : tab.length;
}
else
mc = expectedModCount;
if (tab != null && tab.length >= hi &&
(i = index) >= 0 && (i < (index = hi) || current != null)) {
Node<K,V> p = current;
current = null;
do {
if (p == null)
p = tab[i++];
else {
action.accept(p);
p = p.next;
}
} while (p != null || i < hi);
if (m.modCount != mc)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super Map.Entry<K,V>> action) {
int hi;
if (action == null)
throw new NullPointerException();
Node<K,V>[] tab = map.table;
if (tab != null && tab.length >= (hi = getFence()) && index >= 0) {
while (current != null || index < hi) {
if (current == null)
current = tab[index++];
else {
Node<K,V> e = current;
current = current.next;
action.accept(e);
if (map.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
}
}
return false;
}
public int characteristics() {
return (fence < 0 || est == map.size ? Spliterator.SIZED : 0) |
Spliterator.DISTINCT;
}
}
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {
return new Node<>(p.hash, p.key, p.value, next);
}
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
return new TreeNode<>(hash, key, value, next);
}
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
return new TreeNode<>(p.hash, p.key, p.value, next);
}
void reinitialize() {
table = null;
entrySet = null;
keySet = null;
values = null;
modCount = 0;
threshold = 0;
size = 0;
}
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
Node<K,V>[] tab;
if (size > 0 && (tab = table) != null) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
}
}
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent;
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev;
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
if (root != first) {
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null)
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
return null;
}
final TreeNode<K,V> getTreeNode(int h, Object k) {
return ((parent != null) ? root() : this).find(h, k, null);
}
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
}
moveRootToFront(tab, root);
}
final Node<K,V> untreeify(HashMap<K,V> map) {
Node<K,V> hd = null, tl = null;
for (Node<K,V> q = this; q != null; q = q.next) {
Node<K,V> p = map.replacementNode(q, null);
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
}
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,
boolean movable) {
int n;
if (tab == null || (n = tab.length) == 0)
return;
int index = (n - 1) & hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index], root = first, rl;
TreeNode<K,V> succ = (TreeNode<K,V>)next, pred = prev;
if (pred == null)
tab[index] = first = succ;
else
pred.next = succ;
if (succ != null)
succ.prev = pred;
if (first == null)
return;
if (root.parent != null)
root = root.root();
if (root == null
|| (movable
&& (root.right == null
|| (rl = root.left) == null
|| rl.left == null))) {
tab[index] = first.untreeify(map);
return;
}
TreeNode<K,V> p = this, pl = left, pr = right, replacement;
if (pl != null && pr != null) {
TreeNode<K,V> s = pr, sl;
while ((sl = s.left) != null)
s = sl;
boolean c = s.red; s.red = p.red; p.red = c;
TreeNode<K,V> sr = s.right;
TreeNode<K,V> pp = p.parent;
if (s == pr) {
p.parent = s;
s.right = p;
}
else {
TreeNode<K,V> sp = s.parent;
if ((p.parent = sp) != null) {
if (s == sp.left)
sp.left = p;
else
sp.right = p;
}
if ((s.right = pr) != null)
pr.parent = s;
}
p.left = null;
if ((p.right = sr) != null)
sr.parent = p;
if ((s.left = pl) != null)
pl.parent = s;
if ((s.parent = pp) == null)
root = s;
else if (p == pp.left)
pp.left = s;
else
pp.right = s;
if (sr != null)
replacement = sr;
else
replacement = p;
}
else if (pl != null)
replacement = pl;
else if (pr != null)
replacement = pr;
else
replacement = p;
if (replacement != p) {
TreeNode<K,V> pp = replacement.parent = p.parent;
if (pp == null)
root = replacement;
else if (p == pp.left)
pp.left = replacement;
else
pp.right = replacement;
p.left = p.right = p.parent = null;
}
TreeNode<K,V> r = p.red ? root : balanceDeletion(root, replacement);
if (replacement == p) {
TreeNode<K,V> pp = p.parent;
p.parent = null;
if (pp != null) {
if (p == pp.left)
pp.left = null;
else if (p == pp.right)
pp.right = null;
}
}
if (movable)
moveRootToFront(tab, r);
}
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this;
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0;
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null)
loHead.treeify(tab);
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root,
TreeNode<K,V> p) {
TreeNode<K,V> r, pp, rl;
if (p != null && (r = p.right) != null) {
if ((rl = p.right = r.left) != null)
rl.parent = p;
if ((pp = r.parent = p.parent) == null)
(root = r).red = false;
else if (pp.left == p)
pp.left = r;
else
pp.right = r;
r.left = p;
p.parent = r;
}
return root;
}
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,
TreeNode<K,V> p) {
TreeNode<K,V> l, pp, lr;
if (p != null && (l = p.left) != null) {
if ((lr = p.left = l.right) != null)
lr.parent = p;
if ((pp = l.parent = p.parent) == null)
(root = l).red = false;
else if (pp.right == p)
pp.right = l;
else
pp.left = l;
l.right = p;
p.parent = l;
}
return root;
}
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
x.red = true;
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
return root;
if (xp == (xppl = xpp.left)) {
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root,
TreeNode<K,V> x) {
for (TreeNode<K,V> xp, xpl, xpr;;) {
if (x == null || x == root)
return root;
else if ((xp = x.parent) == null) {
x.red = false;
return x;
}
else if (x.red) {
x.red = false;
return root;
}
else if ((xpl = xp.left) == x) {
if ((xpr = xp.right) != null && xpr.red) {
xpr.red = false;
xp.red = true;
root = rotateLeft(root, xp);
xpr = (xp = x.parent) == null ? null : xp.right;
}
if (xpr == null)
x = xp;
else {
TreeNode<K,V> sl = xpr.left, sr = xpr.right;
if ((sr == null || !sr.red) &&
(sl == null || !sl.red)) {
xpr.red = true;
x = xp;
}
else {
if (sr == null || !sr.red) {
if (sl != null)
sl.red = false;
xpr.red = true;
root = rotateRight(root, xpr);
xpr = (xp = x.parent) == null ?
null : xp.right;
}
if (xpr != null) {
xpr.red = (xp == null) ? false : xp.red;
if ((sr = xpr.right) != null)
sr.red = false;
}
if (xp != null) {
xp.red = false;
root = rotateLeft(root, xp);
}
x = root;
}
}
}
else {
if (xpl != null && xpl.red) {
xpl.red = false;
xp.red = true;
root = rotateRight(root, xp);
xpl = (xp = x.parent) == null ? null : xp.left;
}
if (xpl == null)
x = xp;
else {
TreeNode<K,V> sl = xpl.left, sr = xpl.right;
if ((sl == null || !sl.red) &&
(sr == null || !sr.red)) {
xpl.red = true;
x = xp;
}
else {
if (sl == null || !sl.red) {
if (sr != null)
sr.red = false;
xpl.red = true;
root = rotateLeft(root, xpl);
xpl = (xp = x.parent) == null ?
null : xp.left;
}
if (xpl != null) {
xpl.red = (xp == null) ? false : xp.red;
if ((sl = xpl.left) != null)
sl.red = false;
}
if (xp != null) {
xp.red = false;
root = rotateRight(root, xp);
}
x = root;
}
}
}
}
}
static <K,V> boolean checkInvariants(TreeNode<K,V> t) {
TreeNode<K,V> tp = t.parent, tl = t.left, tr = t.right,
tb = t.prev, tn = (TreeNode<K,V>)t.next;
if (tb != null && tb.next != t)
return false;
if (tn != null && tn.prev != t)
return false;
if (tp != null && t != tp.left && t != tp.right)
return false;
if (tl != null && (tl.parent != t || tl.hash > t.hash))
return false;
if (tr != null && (tr.parent != t || tr.hash < t.hash))
return false;
if (t.red && tl != null && tl.red && tr != null && tr.red)
return false;
if (tl != null && !checkInvariants(tl))
return false;
if (tr != null && !checkInvariants(tr))
return false;
return true;
}
}
}
|