算法算法模板算法模板
小奥算法模板
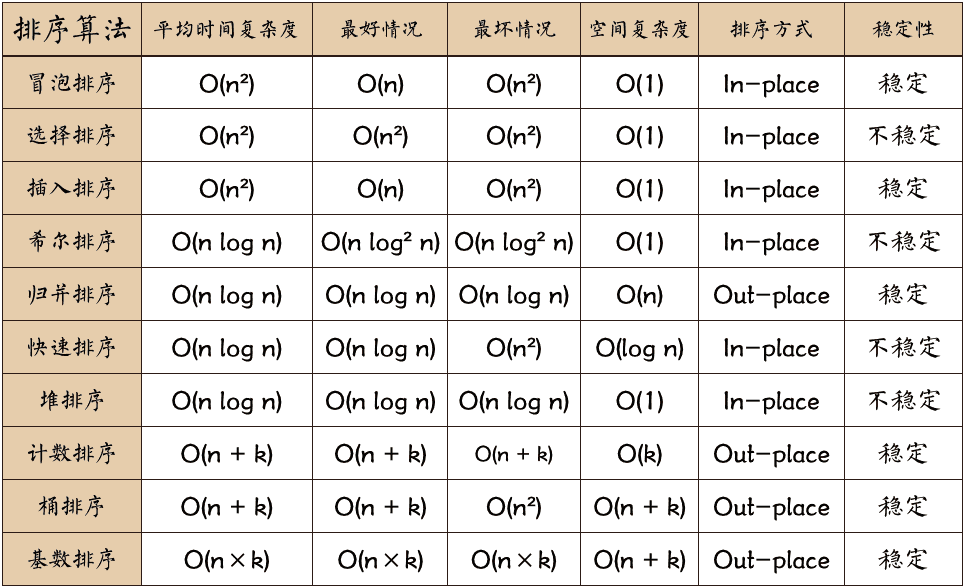
排序算法
十大排序算法指的是在计算机科学中被广泛使用,效率较高且实现简单的十个排序算法。下面是这十种排序算法的简要介绍:
(1)冒泡排序(Bubble Sort):交换相邻元素,最大或最小的元素经过n-1次比较后,就会排在数组的最后一位。
(2)选择排序(Selection Sort):每次寻找未排序序列中的最小值,并将其放在已排序序列的末尾。
(3)插入排序(Insertion Sort):对于未排序序列中的每一个元素,将其插入到已排序序列中的合适位置。
(4)希尔排序(Shell Sort):采用分组策略,先将待排序序列拆分为n/2个子序列,进行插入排序,然后逐渐缩小子序列的长度,直到子序列长度为1,即完成排序。
(5)归并排序(Merge Sort):将待排序序列不断二分,再将两个有序的子序列合并为一个有序序列,重复上述步骤,直到整个序列有序。
(6)快速排序(Quick Sort):选择一个基准元素,将序列中小于它的元素放在它的左边,大于它的元素放在右边,然后递归地对左右子序列进行快速排序。
(7)堆排序(Heap Sort):将待排序序列构建成一个堆,然后不断从堆顶取出最大值,并调整堆,直到取完所有元素。
(8)计数排序(Counting Sort):统计序列中每个元素出现的次数,然后根据统计信息对序列进行重排。
(9)桶排序(Bucket Sort):将整个区间划分为若干个桶,然后将元素按照大小分配到相应的桶中,在桶内使用其他的排序算法(如插入排序)进行排序。
(10)基数排序(Radix Sort):将待排序序列拆分为多个关键字,按照每个关键字进行排序,最终得到有序序列。
以上十种排序算法都有其独特的优势和适用场景,选择合适的排序算法可以提高程序的效率。

冒泡排序
public static void bubblingSort(int[] nums) {
int n = nums.length;
for(int i = 0; i < n; i++) {
for(int j = i + 1; j < n; j++) {
if(nums[i] > nums[j]) {
int t = nums[i];
nums[i] = nums[j];
nums[j] = t;
}
}
}
}
public static void twoWaySort(int[] nums) {
int l = 0, r = nums.length - 1;
while(l < r) {
for(int i = l + 1; i <= r; i++) {
if(nums[l] > nums[i]) {
nums[l] ^= nums[i];
nums[i] ^= nums[l];
nums[l] ^= nums[i];
}
}
l++;
for(int i = r - 1; i >= l; i--) {
if(nums[r] < nums[i]) {
nums[r] ^= nums[i];
nums[i] ^= nums[r];
nums[r] ^= nums[i];
}
}
r--;
}
}
|
选择排序
public static void selectSort(int[] nums) {
int n = nums.length;
for(int i = 0; i < n - 1; i++) {
int minVal = i;
for(int j = i + 1; j < n; j++) {
if(nums[minVal] > nums[j]) {
minVal = j;
}
}
if(minVal != i) {
int t = nums[i];
nums[i] = nums[minVal];
nums[minVal] = t;
}
}
}
|
插入排序
public static void insertSort(int[] nums) {
int n = nums.length;
for(int i = 1; i < n; i++) {
int val = nums[i], j = i;
while(j > 0 && val < nums[j - 1]) {
nums[j] = nums[j - 1];
j--;
}
nums[j] = val;
}
}
|
希尔排序
public static void shellSort(int[] nums) {
int n = nums.length;
for(int g = n >> 1; g > 0; g >>= 1) {
for(int i = g; i < n; i++) {
int x = nums[i];
int j = 0;
for(j = i; j >= g && nums[j - g] > x; j -= g) {
nums[j] = nums[j - g];
}
nums[j] = x;
}
}
}
|
归并排序
借鉴博客链接:(9条消息) java实现归并排序(详解)_java 归并排序_星辰与晨曦的博客-CSDN博客
介绍
归并排序先将待排序的数组不断拆分,直到拆分到区间里只剩下一个元素的时候。不能再拆分的时候。这个时候我们再想办法合并两个有序的数组,得到长度更长的有序数组。当前合并好的有序数组为下一轮得到更长的有序数组做好了准备。一层一层的合并回去,直到整个数组有序。
实现
public static void mergeSort(int[] nums, int l, int r, int[] temp) {
if(l >= r) return;
int mid = l + r >> 1;
mergeSort(nums, l, mid, temp);
mergeSort(nums, mid + 1, r, temp);
int k = 0, i = l, j = mid + 1;
while(i <= mid && j <= r) {
if(nums[i] < nums[j]) {
temp[k++] = nums[i++];
} else {
temp[k++] = nums[j++];
}
}
while(i <= mid) temp[k++] = nums[i++];
while(j <= r) temp[k++] = nums[j++];
for(i = l, j = 0; i <= r; i++, j++) {
nums[i] = temp[j];
}
}
|
快速排序
介绍
实现
public static void quickSort(int[] nums, int l, int r) {
if(l >= r) {
return;
}
int i = l - 1, j = r + 1, x = nums[(l + r) / 2];
while(i < j) {
do i++; while(nums[i] < x);
do j--; while(nums[j] > x);
if(i < j) {
int t = nums[i];
nums[i] = nums[j];
nums[j] = t;
}
}
quickSort(nums, l, j);
quickSort(nums, j + 1, r);
}
public static void quickSortByStack(int[] nums, int l, int r) {
Stack<Integer> s = new Stack<>();
s.push(r);
s.push(l);
while(!s.isEmpty()) {
int low = s.pop(), high = s.pop();
int i = low, j = high;
if(i >= j) {
continue;
}
int pivot = nums[i];
while(i < j) {
while(i < j && nums[j] >= pivot) j--;
nums[i] = nums[j];
while(i < j && nums[i] < pivot) i++;
nums[j] = nums[i];
}
nums[i] = pivot;
s.push(high);
s.push(i + 1);
s.push(i - 1);
s.push(low);
}
}
|
堆排序
import java.util.Scanner;
public class Main{
static int N = 100010;
static int[] h = new int[N];
static int size;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int k = sc.nextInt();
size = n;
for(int i = 1; i < n + 1; i++) {
h[i] = sc.nextInt();
}
for(int i = n / 2; i != 0; i--) down(i);
while(k-- > 0) {
System.out.print(h[1] + " ");
h[1] = h[size];
size--;
down(1);
}
}
public static void down(int u) {
int t = u;
if(2 * u <= size && h[2 * u] < h[t]) t = 2 * u;
if(2 * u + 1 <= size && h[2 * u + 1] < h[t]) t = 2 * u + 1;
if(t != u) {
h[u] ^= h[t];
h[t] ^= h[u];
h[u] ^= h[t];
down(t);
}
}
}
|
计数排序
public static void countSort(int[] nums) {
int n = nums.length;
int[] t = new int[n];
int maxV = nums[0];
for(int i = 1; i < n; i++) {
if(maxV < nums[i]) {
maxV = nums[i];
}
}
int[] count = new int[maxV + 1];
for(int i = 0; i < n; i++) count[nums[i]]++;
for(int i = 1; i <= maxV; i++) count[i] += count[i - 1];
for(int i = n - 1; i >= 0; i--) {
t[count[nums[i]] - 1] = nums[i];
count[nums[i]]--;
}
for(int i = 0; i < n; i++) nums[i] = t[i];
}
|
基数排序
借鉴博客链接:(8条消息) java实现基数排序_基数排序java_其实我不想摆烂的博客-CSDN博客
介绍
属于分配式排序,又称桶子法或者bin sort,顾名思义,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,达到排序的作用。
基数排序的思想是,将所有待比较数值统一为同样的数值长度,数位较短的数前面补0,然后,从最低位开始,依次进行一次排序,这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
实现
public static void radixSort(int[] nums) {
int max = nums[0];
for(int i : nums) max = max > i ? max : i;
int len = (max + "").length();
int[][] bucket = new int[10][len];
int[] bucketCount = new int[10];
for(int i = 0, n = 1; i < len; i++, n *= 10) {
for(int j = 0; j < nums.length; j++) {
int digit = (nums[j] / n) % 10;
bucket[digit][bucketCount[digit]] = nums[j];
bucketCount[digit]++;
}
}
int idx = 0;
for(int i = 0; i < bucketCount.length; i++) {
if(bucketCount[i] != 0) {
for(int j = 0; j < bucketCount[i]; j++) {
nums[idx++] = bucket[i][j];
}
}
bucketCount[i] = 0;
}
}
|
桶排序
借鉴博客链接:(8条消息) java实现桶排序(详细解析)_桶排序java_、信仰_的博客-CSDN博客
介绍
桶排序 (Bucketsort),是一个排序算法,工作的原理是将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(O(n))。
桶排序的思想是,若待排序的记录的关键字在一个明显有限范围内时,可设计有限个有序桶,每个桶只能装与之对应的值,顺序输出各桶的值,将得到有序的序列。简单来说,在我们可以确定需要排列的数组的范围时,可以生成该数值范围内有限个桶去对应数组中的数,然后我们将扫描的数值放入匹配的桶里的行为,可以看作是分类,在分类完成后,我们需要依次按照桶的顺序输出桶内存放的数值,这样就完成了桶排序。
实现
public static void bucketSort(int[] nums) {
int max = nums[0];
for(int i : nums) max = max > i ? max : i;
int[] bucket = new int[max + 1];
for(int i : nums) bucket[i]++;
int idx = 0;
for(int i = 0; i < max + 1; i++ ) {
for(int j = 0; j < bucket[i]; j++) {
nums[idx++] = i;
}
}
}
|
二分查找
二分搜索的三种写法
int binarySearch(int[] nums, int target) {
int l = 0, r = nums.length - 1;
while(l <= r) {
int mid = l + (r - l) >> 1;
if(nums[mid] < target) {
l = mid + 1;
} else {
r = mid - 1;
}
}
return l;
}
int binarySeach(int[] nums, int target) {
int l = 0, r = nums.length;
while(l < r) {
int mid = l + (r - l) >> 1;
if(nums[mid] < target) {
l = mid + 1;
} else {
r = mid;
}
}
return l;
}
int binarySearch(int[] nums, int target) {
int l = -1, r = nums.length;
while(l + 1 < r) {
int mid = l + (r - l) >> 1;
if(nums[mid] < target) {
l = mid;
} else {
r = mid;
}
}
return r;
}
|
二分搜索,左边界和右边界
int left_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
right = mid - 1;
}
}
if (left == nums.length) return -1;
return nums[left] == target ? left : -1;
}
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
left = mid + 1;
}
}
if (left - 1 < 0) return -1;
return nums[right] == target ? right : -1;
}
|
二分答案
:rocket: 875. 爱吃香蕉的珂珂
:rocket: 2187. 完成旅途的最少时间
:rocket: 2226. 每个小孩最多能分到多少糖果
最小化最大值
:rocket: 2439. 最小化数组中的最大值
:rocket: 2513. 最小化两个数组中的最大值
最大化最小值
:rocket: 1552. 两球之间的磁力
:rocket: 2517. 礼盒的最大甜蜜度
:rocket: 2528. 最大化城市的最小供电站数目
TOP K问题
10亿个数中如何高效地找到最大的一个数
将10亿个数据分成1000份,每份每份100万个数据,找到每份数据中最大的那个数据,最后在剩下的1000个数据里面找出最大的数据。 从100万个数据遍历选择最大的数,此方法需要每次的内存空间为10^6*4=4MB,一共需要1000次这样的比较。
10亿个数中如何高效地找到最大的第 K 个数
- 对于top K类问题,通常比较好的方案是分治+hash+小顶堆:
- 先将数据集按照Hash方法分解成多个小数据集
- 然后用小顶堆求出每个数据集中最大的K个数
- 最后在所有top K中求出最终的top K。
- 如果是top词频可以使用分治+ Trie树/hash +小顶堆:
- 先将数据集按照Hash方法分解成多个小数据集
- 然后使用Trie树或者Hash统计每个小数据集中的query词频
- 之后用小顶堆求出每个数据集中出频率最高的前K个数
- 最后在所有top K中求出最终的top K。
- 时间复杂度:建堆时间复杂度是O(K),算法的时间复杂度为O(NlogK)。
TOP K常用的方法
- 快排+选择排序:排序后的集合中进行查找
- 时间复杂度: 时间复杂度为O(NlogN)
- 缺点:需要比较大的内存,且效率低
- 局部淘汰:取前K个元素并排序,然后依次扫描剩余的元素,插入到排好序的序列中(二分查找),并淘汰最小值。
- 时间复杂度: 时间复杂度为O(NlogK) (logK为二分查找的复杂度)。
- 分治法:将10亿个数据分成1000份,每份100万个数据,找到每份数据中最大的K个,最后在剩下的1000*K个数据里面找出最大的K个,100万个数据里面查找最大的K个数据可以使用Partition的方法
- Hash法: 如果这10亿个数里面有很多重复的数,先通过Hash法,把这10亿个数字去重复,这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间,然后通过分治法或最小堆法查找最大的K个数。
- 小顶堆: 首先读入前K个数来创建大小为K的小顶堆,建堆的时间复杂度为O(K),然后遍历后续的数字,并于堆顶(最小)数字进行比较。如果比最小的数小,则继续读取后续数字;如果比堆顶数字大,则替换堆顶元素并重新调整堆为最小堆。
- Trie树: 如果是从10亿个重复比较多的单词找高频词汇,数据集按照Hash方法分解成多个小数据集,然后使用Trie树统计每个小数据集中的query词频,之后用小顶堆求出每个数据集中出现频率最高的前K个数,最后在所有top K中求出最终的top K。
- 适用范围:数据量大,重复多,但是数据种类小可以放入内存
- 时间复杂度:O(Len*N),N为字符串的个数,Len为字符串长度
- 桶排序:一个数据表分割成许多buckets,然后每个bucket各自排序,或用不同的排序算法,或者递归的使用bucket sort算法。也是典型的divide-and-conquer分而治之的策略。
- 使用范围:如果已知了数据的范围,那么可以划分合适大小的桶,直接借用桶排序的思路
- 时间复杂度:O(N*logM),N 为待排序的元素的个数,M为桶的个数
- 计数排序:计数排序其实是桶排序的一种特殊情况。当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
- 适用范围:只能用在数据范围不大的场景
- 时间复杂度:O(N)
- 基数排序:将整数按位数切割成不同的数字,然后按每个位数分别比较。
- 适用范围:可以对字符串类型的关键字进行排序。
- 时间复杂度: O(N*M),M为要排序的数据的位数